by Enrico Franchi - Valerio Maggio for EuroPython 2012
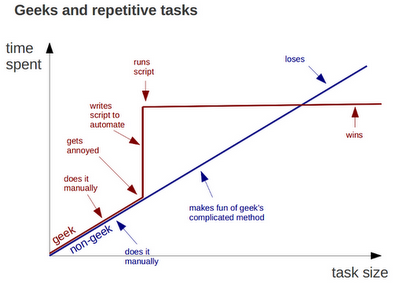
As computer scientists and geeks, we hate repetitive and manual operations and usually prefer making all the processing as automatic as possible (http://jonudell.net/images/geeks-win-eventually.png). Manual operations are boring, time consuming and mostly error-prone and do not allow for any kind of replication or reuse. On the other hand, automatic processing highly promote a better reuse of common operations and may easily scale on problem of different size, from few to very large amount of data.
All such data analysis processes are usually indicated by the term “crunching”, which refers to the analysis of large amounts of information in an automatic fashion, together with its corresponding set of “complex” operations.
Many tools used for data analysis are not overly geek friendly as they require a great deal of repetitive tasks: consider for example the simple case in which we have to collect values obtained by an experimental trial and we have to compute the mean, the minimum and the maximum of such values. A typical solution is copying all the data into an Excel file and to perform all the analysis of interest from there. However, all of these operations become infeasible in real world scenarios where we have to deal with huge amount of data and when “doing things manually” means go ahead by copying and pasting data from several different files.
While other tools, such as Matlab, allow a better automation and offer a more programmer friendly environment, Python offers extremely interesting solutions for these kind of problems. In particular, Python allows to exploits the benefits of a general purpose programming language in combination with a huge number of capabilities for crunching (Numpy, Scipy), data storage (pytables, nosql interfaces), data visualization (matplotlib) and an easy to use interactive environment (iPython, iPython Notebook).
In this talk we present some of the powerful tools available in the Python environment to automatically analyze, filter and process large amount of data. In particular, we present different real-world case studies along with the corresponding working Python code.
Basic maths skills and basic knowledge of the Python programming language are the only suggested prerequisites.


























{kind=link}